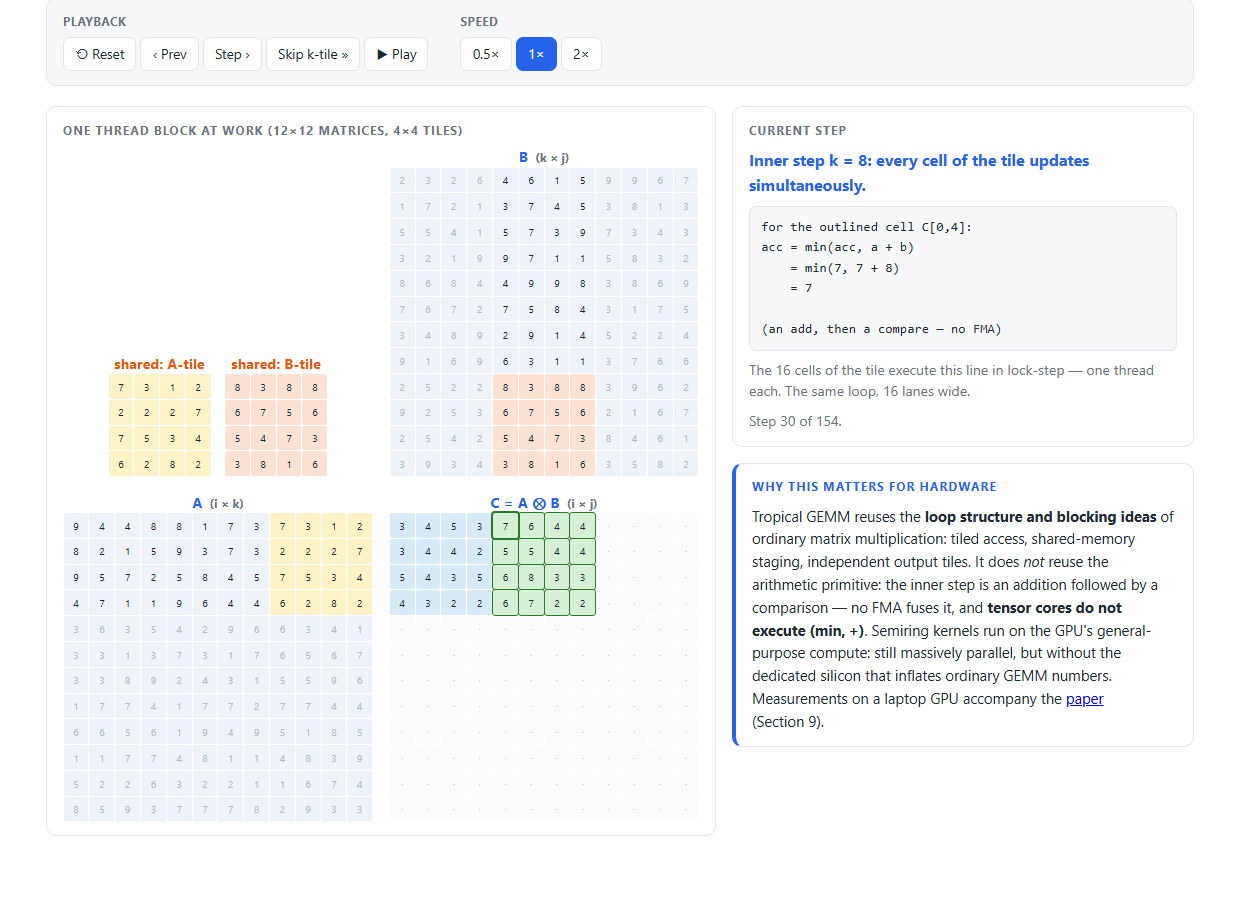
Inside a Tropical GEMM Kernel
Dense tropical matrix multiplication has the loop structure of ordinary GEMM:
for each output tile: acc ← +∞
for each k-tile: load shared A, B
for k in tile: acc = min(acc, a + b)
write back accEverything that makes ordinary GEMM hardware-friendly carries over — tiling, shared-memory staging, independent output tiles. One thing does not: the arithmetic primitive. The inner step is an add followed by a compare; no fused multiply-add executes it, and tensor cores do not apply. This animation walks a thread block through the computation, one shared-memory tile at a time.
What you can do
- Step or play the kernel: select an output tile, stage a 4×4 block of \(A\) and \(B\) into shared memory, sweep the inner \(k\) loop, write back — nine tiles, 154 steps.
- Watch the representative cell’s arithmetic update live:
acc = min(acc, a + b)— an add, then a compare, no FMA. - Use Skip k-tile to move at the granularity of shared-memory loads.
- Read the parallelism annotations: a tile’s 16 cells update in lock-step (one thread block); the nine output tiles are independent (the grid).
The numbers are real: the matrices are fixed 12×12 integer matrices and every displayed accumulator is the true prefix-minimum — the final matrix is the exact min-plus product, pinned as a regression value in the artifact’s spec.
Supporting information
Supporting information for When Addition Becomes Optimization: Tropical Algebra, Paths, Schedules, and Semiring Computation (Section 9: semiring computation on modern hardware), where the corresponding kernels are benchmarked on a laptop GPU.